Order by 源码分析
查询优化器是关系型数据库的核心, 也是 TiDB 代码中最难懂的部分, 这篇文章可以作为 TiDB 查询优化器源码分析的开端, 可能会在文章的过程中掺杂一些跟 Order by 不相关的代码分析. 希望这一个系列能对我跟大家都有帮助.
parser
分析语句的正确方式是从 parser 入手看构造了哪些相关的 ast 结构:
|
|
这里可以看到 oder by 的主要数据结构就是 ast.ByItem:
|
|
plan
然后直接看到 planBuilder.buildSelect:
|
|
这里会给 order by 创建一个 Sort 的逻辑计划:
|
|
我们首先看一下resolveHavingAndOrderBy, 这里会对 oderBY 的 item 执行一遍 havingAndOrderbyExprResolver, 主要是找到 orderBY 中带有聚合函数的相关联的column, 然后把 AggregateFuncExpr 里面的参数替换成对应 selectFields 里面的 SelectField, 然后得到 aggMapper.
|
|
通过 resolveHavingAndOrderBy 的Enter, Leave 我们可以看到, 走到AggregateFuncExpr 的时候, 它会对每一个ColumnNameExpr参数, 调用 Accept, 来 rewrite. 最终可以看到在havingAndOrderbyExprResolver.Leave 的 相应 ColumnNameExpr 处理中, 会把自己转换为 a.selectFields[index].Expr.
|
|
然后对于ast.AggregateFuncExpr 自己, 会在 a.selectFields 中 append 一个辅助的 SelectField 到最后, 并且在a.aggMapper 设置自己在 selectFields 数组中的索引, 方便 Sort 算子使用.
|
|
planBuilder.BuildSort 创建 Logical Plan
下面我们再来看看 BuildSort:
|
|
这里 rewrite 的意思大概是, 比如有一些可以在这个时期就算出来的结果, 就可以做常量折叠, 比如 YEAR('2009-05-19'); 直接可以用 2009 表示, 或者 1 + 1 这种表达式. 当然还有一些其他情况会做转换. TiDB 里面很多用到的是 Visitor 模式, 这里就不详细解释了, OrderBy 子句大部分是 ColumnNameExpr. 这里 rewritor 会通过 func (er *expressionRewriter) toColumn(v *ast.ColumnName) 把它转成对应 Schema 的 Column 对象.
所以到这里 sort.ByItems 就构造完成了, 让我们继续往下看.
Physical Plan
之后会调用 logic.convert2NewPhysicalPlan 将逻辑计划转为物理计划.
对于语句 select * from t order by a;, 它在这里的 LogicalPlan 层级关系是: Sort --> Projection --> DataSource.
调用链大概如下:
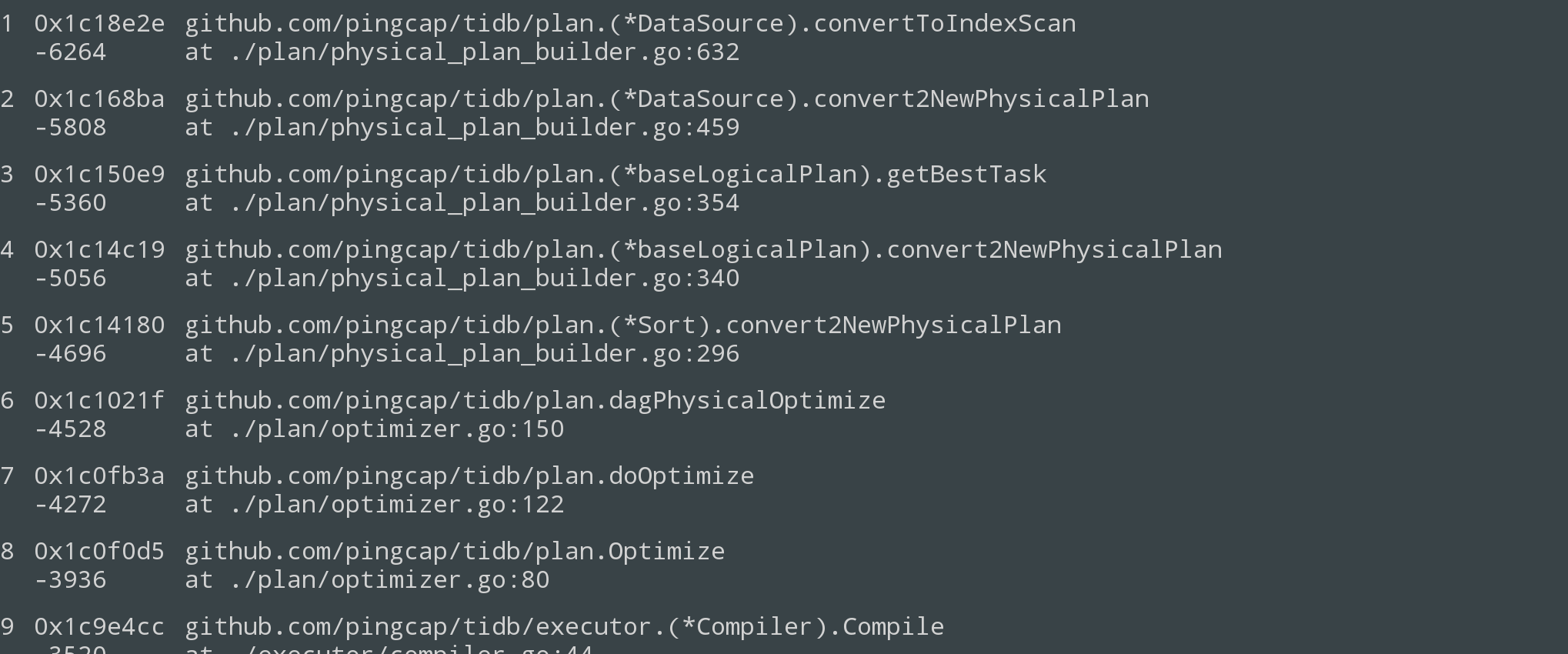
|
|
这里值得注意的是, 在 Sort.convert2NewPhysicalPlan 里面, 分别两次调用了 p.children[0].(LogicalPlan).convert2NewPhysicalPlan, 所不同的只是, 在第二次的时候, 在 requiredProp 里面加入了 order by 相应的列. 这个其实是用来比较两次出来的计划的代价, 来决定是不是下推这个 order by. 然后会把 copTask 的 keepOrder 设置为 true. 如果发现这个 order by 可以下推, 比如刚好 order by 的是主键或者是索引, 那么这个时候就不需要构造一个 Sort 的物理计划了, 直接是一个 PhysicalTableReader 或者 PhysicalIndexReader 或者 PhysicalIndexLookupReader.
具体用到这个 requiredProp 的 cols, 是在 Sort 的 children DataSource 的convertToIndexScan:
|
|
在 baseLogicalPlan.convert2NewPhysicalPlan 大体就是得到一个最优的 task, 然后通过 p.storeTask(prop, t) 存到 p.taskMap 里面:
|
|
之后它会调用到 child 的 DataSource.convert2NewPhysicalPlan. 这里会遍历所有可能的索引, 然后选择一个最小代价的计划.
|
|
DataSource.convertToTableScan
TiDB 里面把读取表的物理计划, 都叫做 TableScan, 它会用一个 range 的对象来表示范围, 如果是全表扫, 那就是[-inc, +inc], 如果是点查, 那就是 [begin, end], begin == end, 所以看看这里是怎么把 DataSource 转为 TableScan的.
对于表:
|
|
执行的操作 select * from t1 where b = 2 order by b;, 我们再来分析下面的函数, 会比较好阐述.
|
|
DataSource.convertToIndexScan
在 DataSource.convert2NewPhysicalPlan 中:
|
|
会尝试把每个 index 都转成 IndexScan:
|
|
在 finishCopTask 里面, 会最终计算task 的 cost, 然后会根据 task 里面的 tablePlan 跟 indexPlan 构造最后的物理计划:
- PhysicalIndexLookUpReader: 如果 tablePlan 跟 indexPlan 都提供
- PhysicalIndexReader: 如果只有 indexPlan
- PhysicalTableReader
getBestTask
这一步是 baseLogicalPlan.convert2NewPhysicalPlan 中调用的, 这里可以看到它会迭代 child 的 convert2NewPhysicalPlan, 把它们都转换成 task 对象. 然后选出最佳的 copTask.
|
|
基本分析到这里, 基本上 sort 的 plan 部分就结束了. 之后就进入到执行器 Executor 部分了, 我们来看看
SortExec
之后代码会进入到 ExecStmt.buildExecutor, 在这里, TiDB 会构造最终的执行器. 对于 Sort:
|
|
有了 SortExec 之后, TiDB 会调用它的 Next() 接口:
|
|
自此, Order by 的代码基本就结束了. 其中还有很多细节没有详细解释, 需要大家看代码去深入了解.